現役NWエンジニアが語る:ネットワーク障害発生時の調査・対応フロー

1.ネットワーク障害の種類 ◆ネットワーク障害とはネットワークが正常に機能しなくなることをいう。インフラの視点で表現するとネットワーク機器に何か不具合が生じて通信が遮断されたり、意図していない挙動をしてしまうことを一般的に指す。ネットワーク障害には大きく2つにカテゴリー分けされる。一つは物理的なネットワーク障害(※図1参照)、もう一つは論理的なネットワーク障害(※図2参照)に分けられる。
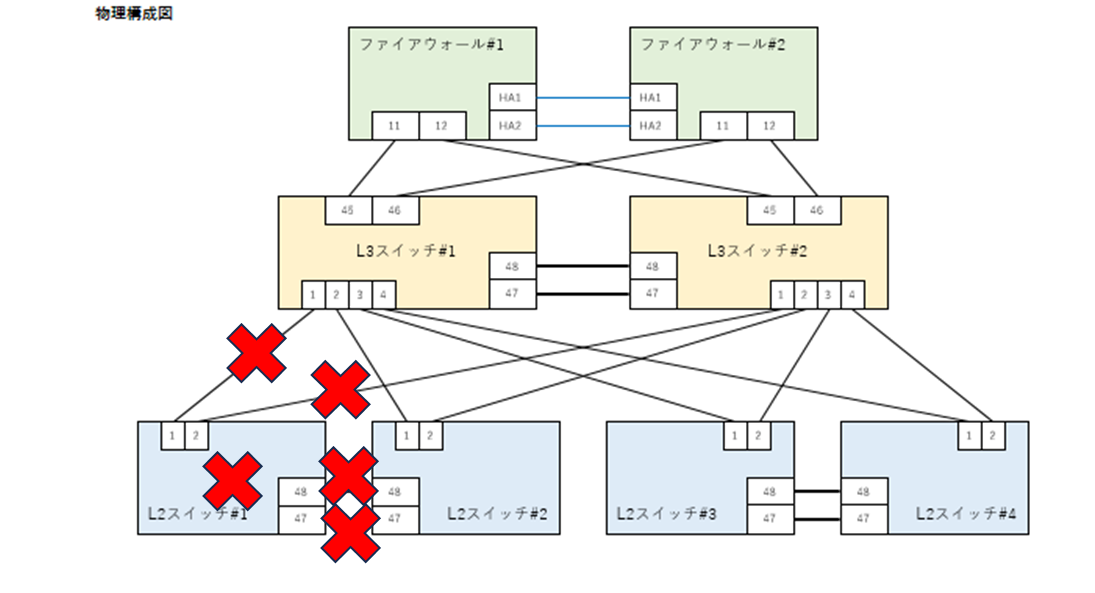
・物理的なネットワーク障害は、ネットワーク機器そのものが故障または、その機器に物理的に繋がっているLANケーブルの断線、抜線、誤ったポートの結線が原因で通信が遮断されることをいう。図1ではL2スイッチ#1が原因で障害が発生している。
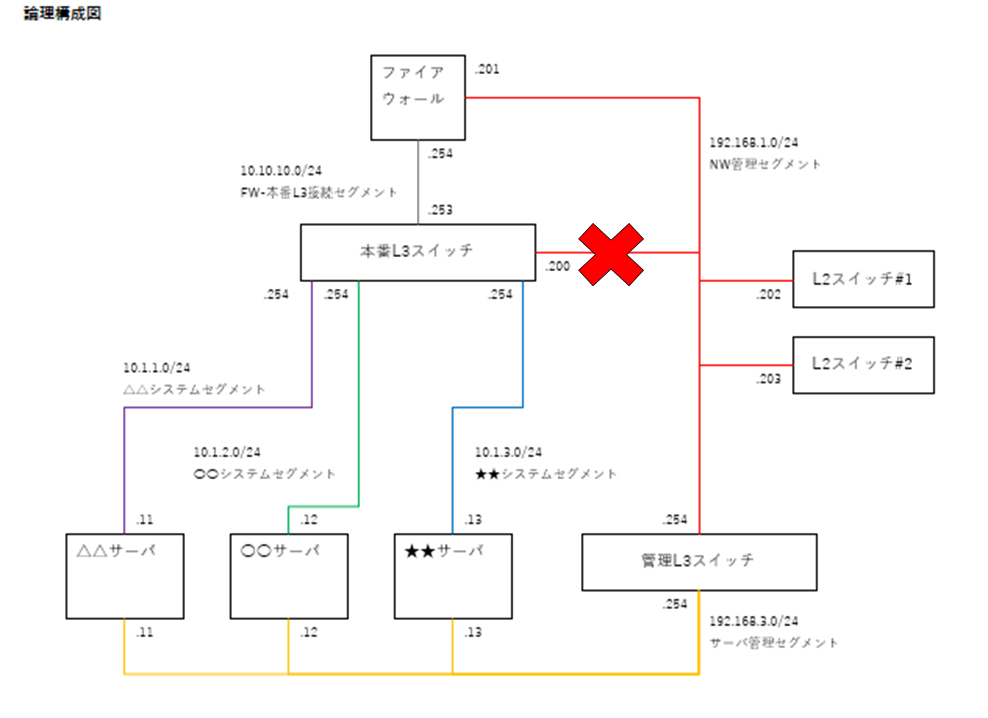
・論理的なネットワーク障害は、ネットワーク機器の設定内容が意図していない挙動をしてしまい通信が上手く通らないことをいう。例えば図2では本番L3スイッチとL2スイッチ間のルーティングやセグメント等が、論理的に誤った内容で設定をしてしまったことが原因で障害が発生している。
✖・・・・断線、抜線、誤ったポートに結線、機器の不具合(物理)、意図していない挙動をした(論理)
※図1
※図2
2.ネットワーク障害発生時の調査方法 ◆ネットワーク障害発生時は以下の図の1から7の順番で原因調査すると良い。 運用保守の案件で障害対応では、下記の図を覚えておけば調査漏れが起きにくい。

ネットワーク障害発生時の調査方法は以下の通りである。
・対象機器のケーブル、ランプ状態を確認 障害が発生した際は、まず客先またはサポートセンターから連絡が来る。そこで障害が発生した機器を指定することが多いので、その機器とその周辺を下記の順番に調査する。
1.対象機器に電源が入っているのかランプ状況を確認。その機器の電源が抜けていないか目視で確認
2.対象機器に結線されているケーブルが、正しく結線されているか、断線していないか、抜けそうになっていないか、ランプ状況が正常なのか目視で確認
物理的なネットワーク障害であれば上記の調査方法で原因が判明する。
・対象機器にログインできるか確認、設定内容、ステータス、ログを確認 障害が発生した際は、検知ツールのアラート、客先またはサポートセンターから連絡が来る。そこで障害が発生した機器を指定することがあるので、その機器とその周辺を下記の順番に調査する。
1.まず対象機器にログインできるか確認
2.隣接機器との通信確認(コマンド→ping xxx.xxx.xxx.xxx)
xxxには隣接機器のIPアドレスを入れる
3.対象機器のログを確認(コマンド→show logging)
4.ログでおおよその対象箇所が分かればステータスを確認 例)インターフェースが疑わしい場合は、show interfaces statusで確認する
論理的なネットワーク障害であれば上記の調査方法で原因が判明する。
3.ネットワーク障害発生時の対応フロー ◆ネットワーク障害発生時の対応フローは大きく6つに分けられる。
1.事象確認 障害発生時に、検知ツールのアラートやユーザーからの苦情から、事象を確認する。この時点で詳細な調査を行うことは初動対応の遅延に繋がる為、重要な点に絞って確認を行う。
2.関連部門への連絡 予め決められたルールに従って関係部門へ連絡をする。詳細情報よりも、迅速な報告が優先される。特に1分1秒を争う緊急度の高い障害発生時は、スムーズにエスカレーションする必要がある。ただし、誤った情報伝達、不明確な報告を行うことは避けなければならない。不明な点がある場合はその事実を正確に伝えるように心掛ける。また、断片的な情報伝達をすることで混乱を招く場合もあるため、報告内容は適切にまとめ、確認中、調査中といった情報のステータスについても伝えるようにする。
3.影響範囲の調査 関係部門への一次連絡後、利用者や業務への影響範囲を調査する。障害の影響範囲を把握し、迅速かつ適切な対応を行うための態勢を決定する。影響範囲の調査では具体的に次のような点を確認することが一般的である。 ・障害が発生した箇所の確認 障害が発生したシステムやアプリケーションなどを特定し、その周辺部分でも問題がないか確認する。調査方法は2.ネットワーク障害発生時の調査方法を参照
・業務影響の調査 システム障害がユーザーや業務にどのような影響を与えるかを調査し、緊急度や対応態勢の決定をする。
・他システムとの関連性の確認 障害が発生したシステムと連携や関係する他のシステムがあれば、そのシステムに影響がないか確認する。
・外部向けのサービス提供の確認 データベースやサーバーへの接続に障害が発生している場合、外部向けサービスの提供にどのような問題が生じているかチェックする。
4.障害原因の調査 システム障害の原因を特定するための調査・分析を行う。問題が発生したシステムやサービスの ログファイルや監視データを調べ、障害が発生した原因を突き止める。ログやシステムの各種レポートを調べても原因を特定できない場合は、まず過去の類似する障害を確認し、仮説をリストアップして検証を繰り返し、原因を絞り込む。関係者が集まって意見を出し合い、ホワイトボード等を使って事象を可視化することが有効である。
5.復旧作業 障害対応の最優先事項は、業務やサービスへの影響を最小限に抑えることである。このため、原因が究明できない場合は、業務やサービスを継続できるよう、まず暫定対応を行うことになる。 ただし、多くの場合、本番環境で復旧作業を行うことになるため、慎重に実施する必要がある。原因が特定され、暫定対応を施した後は恒久対応に移る。恒久対応は、まず作業計画や作業手順を作成する。恒久対応も本番環境で実施することが多いため、復旧作業が与える影響を確認できない場合は、実施の判断基準をあらかじめ関係者とすり合わせする必要がある。これには事前にログ採取方法やデータのバックアップ方法といった基本操作手順を準備すると良い。緊急時にあわてることなくスムーズに作業を進められる。
6.事後対応 障害対応が完了したら、事後対応として関係者に報告書を提出する。報告内容は障害の概要、時系列の事象説明、業務の影響範囲、暫定対応と恒久対応の実施内容、障害原因と対策、再発防止、そして障害分析が含まれます。障害分析には、「なぜなぜ分析」がよく使われる。 「なぜなぜ分析」とは、問題事象の本当の原因を探るための手法として知られ、直接原因だけではなく背後にある根本原因を抽出するために、「なぜ?」を繰り返し問いかけます。通常、5回の「なぜ」を繰り返すことで、根本的な原因を特定できるとされている。また、障害対応の過程で得た技術的な知見やノウハウは、将来のトラブルに対するナレッジの蓄積や対応力向上につながるため、報告書に含めることはもちろん、関係部門への共有が重要だ。
参考資料
https://qiita.com/m-yoshimura/items/2d498a178eee372ba26b
https://envader.plus/article/38




















